Deep Learning: Ein Leitfaden für Menschen ohne Vorerfahrung
Deep Learning ist eine Methode des maschinellen Lernens, mit der Computer simulieren können, wie unser Gehirn funktioniert.
Es handelt sich um eine Methode, bei der Computern beigebracht wird, selbständig zu lernen und Entscheidungen zu treffen, ohne sie explizit zu programmieren.
Statt einem Computer genau zu sagen, was er tun soll, zeigen wir ihm viele Beispiele und lassen ihn so selbst lernen.
Auf Deutsch wird Deep Learning auch ‚mehrschichtiges Lernen‘ oder ‚tiefes Lernen‘ genannt.
Bei Deep Learning lernt der Computer, wie jede Rasse aussieht, indem er viele Beispiele – z. B. Fotos – verarbeitet. Du musst ihm nicht sagen, nach welchen Merkmalen er bei jeder Rasse suchen soll.
Indem du einem Computer viele Fotos von Deutschen Schäferhunden zeigst, kannst du ihn darauf trainieren, diese Bilder zu analysieren und so zu lernen, Deutsche Schäferhunde selbst zu erkennen.
Wurde ein Computer mit einer ausreichend großen Zahl an Daten darauf trainiert, verschiedene Hunderassen zu erkennen, kann er auch bei bisher ungesehenen Bildern erkennen, um welche Rasse es sich handelt.
Viele beliebte KI-Tools wie der Chatbot ChatGPT, virtuelle Assistenten und selbstfahrende Autos wurden mit Deep Learning trainiert.

So funktioniert Deep Learning
Deep Learning funktioniert anhand künstlicher neuronaler Netzwerke (kurz: KNNs).
KNNs ahmen die Struktur des menschlichen Gehirns nach. Ähnlich wie die Neuronen in unserem Gehirn, die miteinander verbunden sind und Informationen senden und empfangen, bilden KNNs virtuelle Schichten, die innerhalb eines Computers zusammenarbeiten.
KNNs bestehen aus mehreren Schichten von Knoten, die auch Neuronen genannt werden. Jedes Neuron erhält Eingaben von der vorherigen Schicht, verarbeitet sie und leitet sie an die nächste Schicht weiter. Auf diese Weise lernt das Modell allmählich, immer komplexere Muster in den Daten zu erkennen.
Es gibt verschiedene Arten von künstlichen neuronalen Netzwerken, aber in seiner einfachsten Form enthält jedes KNN die folgenden drei Schichten:
- Die Eingangsschicht: Hier werden die zu verarbeitenden Daten (z. B. Bilder oder Texte) eingespeist.
- Die verborgenen Schichten: Hier findet das meiste Lernen statt. Der Computer lernt, wichtige Muster und Eigenschaften in den Daten zu identifizieren. Während die Daten durch das Netzwerk fließen, erhöht sich die Komplexität der erlernten Merkmale. Beim Beispiel des Hundebilds könnte die erste verborgene Schicht lernen, einfache Muster wie die Ränder eines Bildes zu erkennen. Die letzte verborgene Schicht könnte lernen, wie man komplexere Merkmale wie Textur oder Form erkennt. Schließlich kann das Netzwerk bestimmen, welche Merkmale (z. B. das Gesicht) am wichtigsten sind, um eine Hunderasse von einer anderen zu unterscheiden.
- Die Ausgabeschicht: Hier wird die endgültige Vorhersage oder Klassifikation gemacht. Wenn das Netzwerk darauf trainiert ist, Hunderassen zu erkennen, könnte die Ausgabeschicht die Wahrscheinlichkeiten angeben, mit der es sich bei der Eingabe um einen Deutschen Schäferhund oder eine andere Rasse handelt.
Es ist auch möglich, ein Deep-Learning-Modell rückwärts zu trainieren, von der Ausgabe zur Eingabe. Dieser Prozess ermöglicht es dem Modell, Fehler zu berechnen und Anpassungen vorzunehmen, damit die nächsten Vorhersagen oder andere Ausgaben genauer sind.

Deep Learning vs. Maschinelles Lernen
Deep Learning ist eine spezialisierte Form des maschinellen Lernens, die entwickelt wurde, um das maschinelle Lernen effizienter zu machen. Im Wesentlichen ist Deep Learning eine Weiterentwicklung des maschinellen Lernens.
Machinelles Lernen (ML) ist eine Untergruppe der künstlichen Intelligenz (KI). Bei diesem Bereich der Informatik wird Maschinen beigebracht, Aufgaben auszuführen, die normalerweise mit menschlicher Intelligenz in Verbindung gebracht werden. Dazu zählen etwa das Treffen von Entscheidungen und sprachbasierte Interaktionen.
Beim maschinellen Lernen werden Computerprogramme entwickelt, die auf Daten zugreifen und sie verwenden können, um selbstständig zu lernen. Allerdings unterscheiden sich Deep Learning und maschinelles Lernen in Bezug auf
- die Daten, mit denen sie arbeiten und
- die Methoden, mit denen sie lernen.
Daten und Methoden des maschinellen Lernens
Traditionelles maschinelles Lernen erfordert strukturierte, beschriftete (d. h., klar gekennzeichnete) Daten (z. B. quantitative Daten in Form von Zahlen und Werten). Menschliche Fachkräfte identifizieren manuell relevante Merkmale in diesen Daten und entwerfen daraus Algorithmen (= eine Liste an Schritt-für-Schritt-Anweisungen) für den Computer.
Anhand dieser Algorithmen kann der Computer ähnliche Merkmale verarbeiten. Maschinelles Lernen ist stärker als Deep Learning auf menschliches Eingreifen angewiesen, um zu lernen.
Daten und Methoden des Deep Learnings
Im Gegensatz zum maschinellen Lernen können Deep Learning-Modelle unstrukturierte Daten wie Audiodateien oder Social-Media-Posts verarbeiten. Das ermöglicht es ihnen, ohne menschliches Eingreifen herauszufinden, wie sich verschiedene Kategorien von Daten voneinander unterscheiden.
Mit anderen Worten: Ein Deep Learning-Modell benötigt nur Daten und eine Aufgabenbeschreibung, und lernt selbst, wie es seine Aufgabe erfüllen kann.
| Deep Learning | Maschinelles Lernen (ML) |
|---|---|
| Eine Untergruppe des maschinellen Lernens | Eine Untergruppe der künstlichen Intelligenz |
| Benötigt große Datensätze für das Training | Kann anhand kleiner Datensätzen trainiert werden |
| Lernt selbstständig | Menschliches Eingreifen ist erforderlich, um Fehler zu korrigieren und das Lernen zu verbessern |
| Arbeitet mit unstrukturierten Daten (z. B. Text, Audiodateien, Social-Media-Posts) | Benötigt strukturierte Daten (z. B. Daten, Namen, Kreditkartennummern) |
| Verbessert sich kontinuierlich, wenn die Größe des Datensatzes zunimmt | Erreicht eine bestimmte Leistungsgrenze |
| Benötigt viel Rechenleistung | Benötigt weniger Rechenleistung |
Diese Arten von Lernen gibt es
Deep Learning und maschinelles Lernen funktionieren über verschiedene Lernmethoden:
Überwachtes Lernen
Überwachtes Lernen wird angewendet, wenn die Trainingsdaten beschriftet sind. Das heißt, die richtige Antwort ist enthalten.
Unüberwachtes Lernen
Unüberwachtes Lernen bedeutet, dass das Lernen anhand nicht beschrifteter Daten stattfindet. Der Algorithmus erkennt Muster in den Daten und klassifiziert die Informationen selbst.
Der Algorithmus lernt, wie er Tiere, die zur gleichen Art gehören, selbstständig gruppieren kann, indem er Ähnlichkeiten und Unterschiede erkennt.
Bestärkendes Lernen
Bestärkendes Lernen bedeutet, dass der Algorithmus durch Belohnungen und Bestrafungen lernt.
Das tiefe Verstärkungslernen ist eine spezialisierte Form des bestärkenden Lernens, die tiefe neuronale Netzwerke nutzt, um komplexere Probleme zu lösen.
Die Rolle von KI im Deep Learning
Künstliche Intelligenz (KI) ist die Wissenschaft, bei der Computer entwickelt werden, die menschliche Fähigkeiten nachahmen – z. B. Sehen, Verstehen, Empfehlungen abgeben.
Deep Learning ist der Versuch, nachzuahmen, wie Menschen bestimmte Arten von Wissen erlangen.
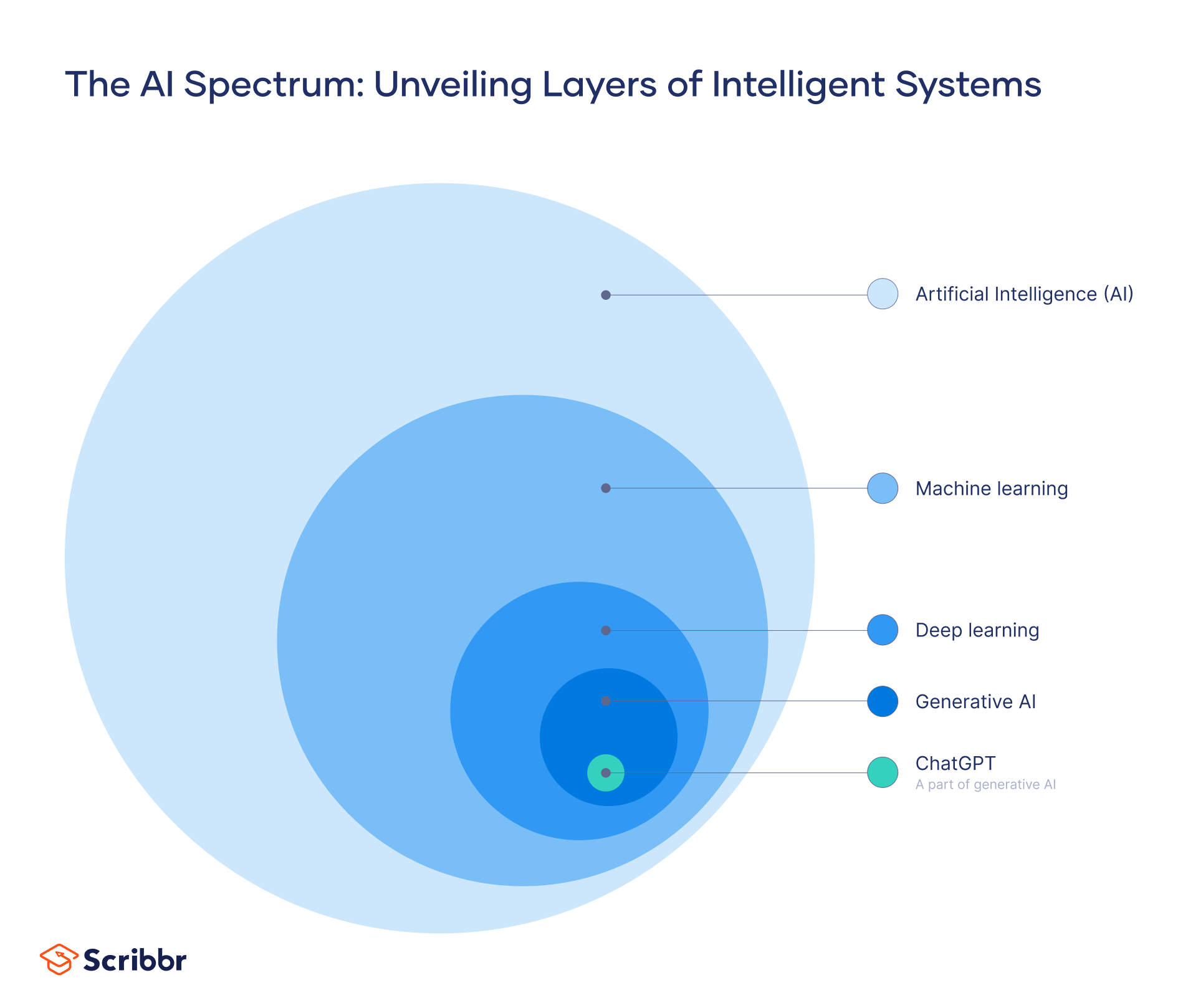
KI stellt den übergeordneten Rahmen und Konzepte zur Verfügung, die Deep-Learning-Algorithmen und -Modelle leiten. Innerhalb des Feldes des Deep Learnings hilft KI bei der Definition von Zielen sowie den dafür eingesetzten Methoden.
KI stellt die Prinzipien und Techniken zur Verfügung, um künstliche neuronale Netzwerke (KNNs) zu entwickeln und zu trainieren. Diese KNNs können komplizierte Muster in großen Datenmengen erkennen.
Darüber hinaus basiert die Bewertung und Optimierung von Deep-Learning-Modellen auf KI. Sie hilft dabei, zu bestimmen, welche Modellarchitektur, Parameter und Trainingsverfahren am besten für ein bestimmtes Problem oder eine bestimmte Aktivität geeignet sind.
Generative KI stützt sich oft auf Deep-Learning-Modelle, um neue und originelle Inhalte zu erstellen.
ChatGPT basiert zum Beispiel auf einem neuronalen Deep-Learning-Netzwerk, das Large Language Modell (LLM) genannt wird.
Dieses Netzwerk wurde mithilfe großer Datenmengen aus dem Internet trainiert – z. B. Websites, Bücher, Nachrichtenartikel und mehr. ChatGPT nutzt dieses Training, um Text zu generieren, Fragen zu beantworten und Dokumente zusammenzufassen.
Wofür Deep Learning benutzt werden kann
Deep Learning kann in vielen Bereichen angewendet werden und erweitert ständig die Grenzen dessen, was Computer leisten können. Hier sind einige alltägliche Anwendungen von Deep Learning.
Personalisierte Empfehlungen
Video-Streaming-Dienste wie Amazon oder Netflix lernen deine Vorlieben kennen, um dir an dich angepasste Vorschläge zu machen. Wenn du einen Film oder eine Serie bis zum Ende anschaust oder in deine Bibliothek aufnimmst, zeigst du damit, dass dir dieser Inhalt gefällt. Basierend darauf aktualisiert der Dienst seine Algorithmen, um dir genauere Empfehlungen zu geben.
Als studierende Person können dir auf Online-Lernplattformen personalisierte Empfehlungen gemacht werden. Dabei werden dir auf der Grundlage deiner Interessen und deines Lernverlaufs relevante Kurse oder Lernmaterialien vorgeschlagen.
Verarbeitung natürlicher Sprache
Computer können die menschliche Sprache mit zunehmender Genauigkeit in gesprochener und geschriebener Form verstehen und verarbeiten. Diese Fähigkeit hat ein breites Spektrum an Anwendungen, von Chatbots und sprachgestützten Assistenten bis hin zu Tools zum Zusammenfassen oder Umschreiben von Texten.
Zudem können Deep-Learning-Systeme zur Stimmungserkennung von Social-Media-Posts verwendet werden. Dabei wird untersucht, ob Menschen einer Marke, einem Produkt oder eine Fragestellung gegenüber positiv, negativ oder neutral eingestellt sind.
Computer Vision
Computer Vision ist die Fähigkeit von Computern, Objekte zu erkennen und nützliche Informationen aus Bildern oder Videos zu extrahieren. Mithilfe von Deep Learning können Computer auf eine ähnliche Weise wie Menschen verstehen, was sie ‚sehen‘.
Dadurch können selbstfahrende Fahrzeuge Verkehrsschilder und Fußgänger erkennen. Auch bei der Moderation auf sozialen Netzwerken wird die Anwendung genutzt, um unsichere oder unangemessene Inhalte automatisch zu blockieren. In der Modeindustrie ermöglicht sie das virtuelle Anprobieren von Kleidung.
Vorteile und Einschränkungen von Deep Learning
Deep Learning hat eine Reihe von Vorteilen und Einschränkungen.
Vorteile
- Deep-Learning-Algorithmen können sowohl strukturierte als auch unstrukturierte Daten verarbeiten, ohne auf menschliche Hilfe angewiesen zu sein. Deep Learning ist eine hervorragende Methode, um komplexe Muster und Beziehungen in Daten zu erkennen. Dies macht sie für Aufgaben wie Bilderkennung, Verarbeitung natürlicher Sprache und Spracherkennung geeignet.
- Deep Learning ermöglicht Unabhängigkeit bei der Merkmalextraktion. Merkmalextraktion ist der Prozess, bei dem wichtige Muster oder Eigenschaften in Daten gefunden und markiert werden, die für das Lösen einer bestimmten Aufgabe relevant sind.
- Die Genauigkeit verbessert sich bei Deep Learning im Laufe der Zeit mit mehr Training und mehr Daten.
- Durch Deep Learning kann ein Computer sich selbst korrigieren. Nach dem Training benötigt er wenig (oder gar kein) menschliches Eingreifen.
Einschränkungen
- Die Erkenntnisse, die durch Deep Learning gewonnen werden, sind nur so gut wie die Daten, mit denen das Modell trainiert wurde. Fehlerhafte oder nicht repräsentative Trainingsdaten, die etwa historische Ungleichheiten widerspiegeln, können dazu führen, dass einige Deep Learning-Modelle menschliche Voreingenommenheiten (‚Bias‘) bezüglich Ethnie, Geschlecht, Alter usw. replizieren oder verstärken. Dies wird als algorithmische Voreingenommenheit bezeichnet.
- Deep-Learning-Modelle erfordern zur Durchführung von komplexen mathematischen Berechnungen viel Rechen- und Speicherleistung. Diese Hardwareanforderungen können kostspielig sein. Darüber hinaus benötigt diese Methode im Vergleich zu anderen Methoden des maschinellen Lernens mehr Zeit für das Training.
- Deep-Learning-Modelle haben ein sogenanntes ‚Black-Box‘-Problem. Das bedeutet, dass der Entscheidungsfindungsprozess undurchsichtig ist und nicht auf eine Art und Weise erklärt werden kann, die für Menschen leicht verständlich ist. Wenn zum Beispiel ein selbstfahrendes Fahrzeug einen Fußgänger verletzt, können wir den ‚Gedankenprozess‘ des Modells nicht immer nachvollziehen. Dadurch können wir nicht immer feststellen, welche Faktoren zu diesem Fehler geführt haben.
Weitere interessante Artikel
In unserer Wissensdatenbank findest du weitere anschauliche Artikel zur Nutzung von KI-Tools, alles rund um das Thema Plagiat und zum richtigen Zitieren von Quellen..
KI-Tools nutzen
Häufig gestellte Fragen
Diesen Scribbr-Artikel zitieren
Wenn du diese Quelle zitieren möchtest, kannst du die Quellenangabe kopieren und einfügen oder auf die Schaltfläche „Diesen Artikel zitieren“ klicken, um die Quellenangabe automatisch zu unserem kostenlosen Zitier-Generator hinzuzufügen.
Solis, T. (2023, 28. Juni). Deep Learning: Ein Leitfaden für Menschen ohne Vorerfahrung. Scribbr. Abgerufen am 1. Juli 2026, von https://www.scribbr.de/ki-tools-nutzen/deep-learning/
